项目开发笔记(十)
最近真是繁忙,公司项目 业余项目都同步推进中
公司的项目最近略有松散,但是感觉自己也应该做到了称职。按照公司目前的项目开发模式,可以预见未来很长一段时间都会处在一种 改 改 改 改 的节奏中。在这种节奏下 很容易把代码写烂,在很多次产品改需求 催进度的时候 我都时刻暗示自己 不要因为时间紧迫,而生产垃圾代码,不要因为功能变动,而产生过多硬编码,从这种角度来看 可能这种开发模式可以磨练人呢。
业余项目最近也处在最关键的一个阶段,业余项目的一个好处就是 我可以把任意一个地方模块 写成我自己想要的样子,我不用担心任何人破坏我原本的代码思路,我可以无限次重构 直到自己觉得优雅为止。可喜可贺的是,业余的项目终于可以产生收益了 Orz,之前的独立游戏 也有国外渠道愿意推广(太有眼光了),虽然对独立游戏的收益不抱希望。不管这些事情结果如何 都感谢大家的赏识。
好了,我们接下来扯今天要分享的技术内容。针对Unity使用c#脚本编写逻辑的项目,逻辑代码的保护也就是DLL文件的防反编译(Anti-Decompile) 目前市面上还没有一套完整的方案。
一般的防破解思路
在软件保护中 一般分为 客户端软件的保护 和 web软件的保护。客户端软件一般的防破解思路基本都一致,无论是win/OSX/Linux/Android/iOS 还是其他单片机上的软件程序。防破解的做法都是从 静态保护,动态保护 两个方面着手。有可能很多其他地方管着两种方式的命名不一样。通俗的叫法应该是 防止静态反编译 防止动态反编译。
静态反编译(Static decompile)
所谓的静态反编译,就是在不调试的情况下根据软件的本体去查看实现逻辑或者原理(Q.普通没代码的软件也可以调试? A.一般无论是什么系统 Win Linux Android OSX iOS,其核心库 – Kernel层中都会带有调试功能的API,即使是在发行版本的操作系统中 这些调试接口也会被保留,而这些调试接口可以调试任意User层的软件,而我们开发的大多都是属于User层的软件。)
举几个例子:
使用Dex2jar工具对安卓安装文件APK进行导出jar,就属于一种针对安卓软件的静态反编译技术,
使用IDA OD等工具对 .exe .dll进行反编译 也算是一种针对win平台软件的静态反编译的行为。
使用JDgui工具对jar进行查看代码,也算是针对Java软件的一种静态反编译行为
静态反编译技术可以应用在什么地方?
一般的单机小游戏破解,普通防御水平的单机游戏破解 部分商业软件的离线暴力破解 都可以用得上静态反编译技术。它并不是一个针对性很强的学科技术 而是一阵套破解软件的方式。
动态反编译(Dynamic decompile)
所谓的动态反编译,就是与静态反编译相对而言的 在软件运行过程中对软件进行逆向或者实现原理分析的技术。一般软件破解 都会首先尝试静态反编译,在静态反编译无果 或者获取的信息不够的情况下 大家才会使用动态反编译技术。与动态反编译相辅相成的技术叫做动态调试。之前说过 每个操作系统 都有提供调试软件的API接口,大多数的动态调试工具 都是根据这些API而实现的。可以把动态调试 理解为 Unity 的内存分析工具,在软件启动运行的过程中 获取你想要的信息 而最后达到破解的目的。
动态调试 强调的一个字就是 “动”,所以技术难度会普遍比静态反编译高一个量级。目前我熟知的win上的动态调试工具 有OD,winDBG。大家有兴趣 不妨去试一试。
关于代码混淆
搜索引擎上可获得的普遍方法是:c#逻辑代码混淆,但是代码混淆对于我们的项目,或者说是对于大多数的项目都不适用。这里要说说什么是代码混淆。代码混淆的反义词是提高代码可读性,一般程序员写代码都力争做好代码的可读性,命名可直译的变量名 ; 减轻“眼球paser”的压力;缩短函数的代码行数。代码混淆的主要思想是在不影响代码正常运行的情况下把代码的可读性降到最低,举个例子:
// 代码混淆前 - 某函数长这样
void GotoFly()
{
int nDelTime = 1000.0f; // seconds
_Doit(nDelTime);
}
以上这段代码,直接使用眼球paser就可以知道大概意思是:1000秒后起飞~
// 代码混淆后
void x()
{
int x = 1000.0f;
_x(x);
}
以上代码,直接使用眼球paser根本看不出什么意思。但是并不影响计算机执行它
以上就是代码混淆的主要思路和原理。基于此,我决定不在我们项目上使用代码混淆的理由是:
理由1 – 这是由于Unity仅仅把C#当成一种脚本解析导致的。过度的代码混淆 会让Unity底层无法识别出根据不同方式加载(静态加载 动态加载)的游戏体 或者是 脚本对象。代码混淆还会照成某些反射功能的失效(PS:这个观点并没有经过严格的自我论证)
理由2 – 目前我们的原生(objective-c java)代码和C#之间的调用,是使用UnitySendMessage函数,这个函数的实现原理是直接传入函数名字字符串,然后去程序集的函数表根据字符串搜索找到具体的函数体。也就是说 函数名字不能改变,否则就会无法被搜索到。这与代码混淆的具体做法相冲突(函数名混淆)。
理由3 – 代码混淆目前还没找到一款完美的工具,C#的混淆和java的混淆不同,Android项目中Java的混淆工具已经被SDK自带且应用得非常广泛了。
关于DLL文件
Unity会把启动代码编译成一个名为Assembly-CSharp.dll的DLL库文件。这种DLL文件是一种可移植的可执行文件 – 传送门.
一般win系统下的大多数应用程序都是这种格式的文件。
文件的数据结构
可能很多同学并不清楚,大多数的文件,无论是 PE文件(.DLL,.EXE),还是图片文件(.png,.jpg,.jpeg),文档文件(.doc,.csv,.exls,.sh,.mk),媒体文件(.mp3,.mv,mp4,.avi),特定平台文件(.apk,.ipa),其他文件(.jar,.lib,.so,.a)等等一切的文件,其实都是由不同的编码(ASCII , UTF-8 ,UNICODE,UTF-16),不同的压缩格式(二进制,非压缩)组成的。是根据什么组成的?是根据文件发明者设定的一种通用的数据结构组合而成的。换言之,我们每个人都可以发明一种数据结构 由它组合成一种我们自己自定义的文件格式。所以说 几乎每一种文件 都具有他的数据结构,编码格式,储存格式。
理解了每一种文件都具有数据结构之后 我们再回头来看DLL文件。以下是这种文件格式的基本数据结构:
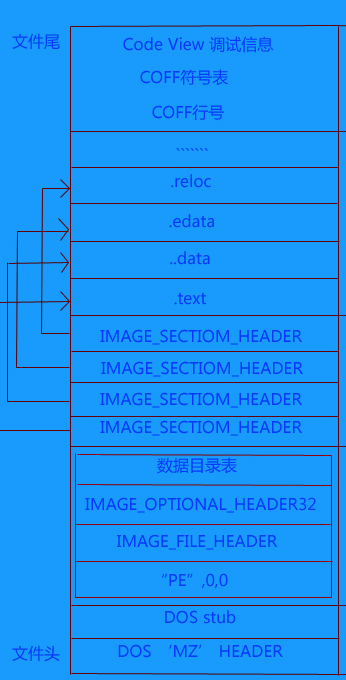
题外话 – Q. 我是怎么知道这种文件的数据结构的?
A. Win系统经过十数年的发展,虽然PE文件结构从未对外公布详细数据结构,但是早已经被逆向业内分析透了。这里对DLL文件数据结构就不再过多解释了,如果想详细的了解这种数据结构,推荐书籍 – 加密与解密 。
DLL反编译软件的原理
所谓知己知彼百战不殆,反编译或者破解DLL文件一般使用的软件有: ILSpy – 反编译成C#代码,NET Reflector – 反编译成C#代码,OD – 反编译成汇编代码,IDA – 反编译成汇编代码,PEID – 查看文件详细结构并修改DUMP等, 还有一些个人开发作品 应用范围并不广的这里不再提。
这里众多的工具中 的基本原理都是 – 提取分析并利用PE数据结构。根据数据结构取得 文件头,函数表,重定位表,调试信息,资源表,代码表 然后根据不同工具的作用 来利用不同的信息。
换言之,很多的工具反编译DLL的第一步,就是解析DLL文件结构.
剑锋对麦芒
上面的篇幅介绍了关于获取软件实现细节(破解,反编译)的一般思路和手段,还介绍了大家一般使用的工具们。所谓剑锋对麦芒 我们的DLL防护也应该从如何防止被这类工具识别或者反编译入手 – 打乱DLL的数据结构。在这之前,介绍一下目前项目的对Unity逻辑代码的加载方式(一般DLL热更的加载方式)。
- Unity项目的逻辑代码加载方式(Android)
看如下代码
//-------------------------------------------------------------------------
private void LoadGameLoaderAtAndoridExternal(string path, string componentName)
{
byte[] pBuffer = File.ReadAllBytes(path);
int nLenght = pBuffer.Length;
Assembly assembly = Assembly.Load(pBuffer);
Type component = assembly.GetType(componentName);
gameObject.AddComponent(component);
}
//-------------------------------------------------------------------------
方式是:
- 使用File.ReadAllBytes加载进入内存
- Assembly.Load从外部加载进程序集
- 使用传入脚本名字字符串的方式获取特定的脚本 挂接到游戏体上
- Over
这种方式加载在 【1】 之后DLL会被放在内存的一个缓冲区中,代码中的 pBuffer 就是内存区的指针(DOUBLE WORD 大小的指针)。在【2】的时候把内存的指针传入,基于此 我们可以在【1】【2】 之间 对pBuffer所指定的内存区做任何我们想要做的修改。(由于这个内存区已经被申请,并非系统所占用 所以怎么修改 都不会产生异常 或者其他断点)。明白了这一点之后 我们在安卓平台上对DLL做的防护基本原理就呼之欲出了:
在DLL打包进APK 或者 上传到服务器准备热更新之前:
- 打乱DLL的数据结构,对里面的关键数据加密 – DLL加密
- Over
在Unity项目中
- 使用File.ReadAllBytes加载进入内存
- 调用写好的解密算法,对DLL所在的内存区进行解密 – DLL解密
- Assembly.Load从外部加载进程序集
- 使用传入脚本名字字符串的方式获取特定的脚本 挂接到游戏体上
- Over
基本的代码可以是:
//-------------------------------------------------------------------------
private void LoadGameLoaderAtAndoridExternal(string path, string componentName)
{
byte[] pBuffer = File.ReadAllBytes(path);
int nLenght = pBuffer.Length;
// DLL解密操作
__goToDecry_(pBuffer, nLenght);
Assembly assembly = Assembly.Load(pBuffer);
Type component = assembly.GetType(componentName);
gameObject.AddComponent(component);
}
//-------------------------------------------------------------------------
[DllImport("aasdymanic")]
private static extern void __goToDecry_(byte[] pBuffer, int nBufferLen);
//-------------------------------------------------------------------------
题外话 – 这里详细解释一下指针(可能有同学没接触过C/C++ ASM等底层语言)。在我们的编程语言里 其实一切对象皆指针。在我们的操作系统中 指针一般都是一个大小为 DOUBLE WORD = 2 WORDs = 2*8 Byte = 16 Bytes 的数据。这个数据指向程序运行内存的某一个地方。
Q. 什么是程序运行内存啊?
A. 在32位机器的所有操作系统里,每一个程序都会分配虚拟内存(4G) 内存范围为 0x00000000~0xFFFFFFFF ,这个并不是我们电脑里内存条那个真实的内存,而是一个通过缓存区快速转换形成的虚拟内存,但是在用户程序看来 他就是一个 0x00000000~0xFFFFFFFF范围的连续性的内存段。所谓的指针,就是指向 这个4G大小的内存的任意一个位置的 双字大小的一个数据。之前说的加载DLL到内存 就是把整个DLL文件加载到 这个4G内存的某一个地方(是在4G内存的那个地方?一般这个4G内存 系统会分某一段给应用程序 分某一段留给系统调用 ,这个DLL就被加载到应用程序可用的那个地方里)。
说回上一段代码,注意代码中的 __goToDecry_ 函数,我在这个函数中传入了DLL所在内存的内存指针和DLL大小。这就相当于限定了我们安全修改的内存区域范围,在这个函数中 我们做DLL解密操作 会非常安全,绝对不会修改到非DLL的内存区域数据。
__goToDecry_ 函数使用Android提供的NDK C++写在.so库中(若想再加强安全,可以针对so库进行加壳加固)
针对这个思路,我在我们项目中实现了一套加密方案.
- Unity项目的逻辑代码加载方式(iOS)
目前iOS端的方式并非分DLL加载运行,而是全部脚本集中到一起编译成一个DLL打包到IPA中,由于iOS下不支持JIT 只支持AOT,iOS AppStore更新不支持更新可执行的资源文件(目前uLua脚本,C#Light还可以热更新)
JIT – Just In Time 即时编译
AOT – Ahead Of Time 静态编译 就是 运行前编译
所以在iOS中无法使用Assembly反射机制来热更新代码,固在iOS端中就不能使用Android端那种加密DLL的方式了。起初我想采用破解libiPhone-lib.a(Unity核心库)的方式在解释DLL脚本之前 加入DLL加密操作,起初的想法是,把整个打包运行流程改为:
打包
- Unity编辑器导出Xcode项目
- 在导出Xcode项目的时候对Assembly-CSharp.dll进行加密 – DLL加密
- 编译Xcode项目
- 生成iPA安装文件
运行
- 启动Unity项目
- 在加载Assembly-CSharp.dll的中途进行解密操作 – DLL解密
这种思路我目前并没有验证是否可行,因为我发现了另外一种更快捷的方式 – 脚本剥离 Stripping Level
iOS For Unity的项目中 打包DLL 是使用事先生成 .s 文件的方式,所谓 .s 文件正是为AOT准备的静态编译文件,.s文件对于于每一个DLL文件
// .s文件片段
// 来自 xcode项目下的 Libraries/Assembly-CSharp.dll.s
#if defined(__arm__)
.text
.align 3
methods:
.space 16
.align 2
Lm_0:
m_BHMoveLine__ctor:
_m_0:
.byte 13,192,160,225,128,64,45,233,13,112,160,225,0,89,45,233,8,208,77,226,13,176,160,225,0,0,139,229,0,0,155,229
.byte 100,16,160,227,56,16,128,229
bl p_1
.byte 8,208,139,226,0,9,189,232,8,112,157,229,0,160,157,232
Lme_0:
.align 2
Lm_1:
m_BHMoveLine_Start:
_m_1:
从内容上看 似乎是Unity把DLL翻译成ASM代码了. 暂时不明白为何要生成这类文件(需深入了解XCODE项目的编译流程和引用库类型之后才能给出更合理的解释)
基于此,我选择使用Unity的脚本剥离功能,让我们对比下使用了剥离功能后的两个DLL反编译对比:
// 未剥离的某函数
// 使用了剥离的某函数

使用了剥离功能之后的 DLL 把每一个函数的实现都抽离了,这恰恰实现了我们 保护DLL逻辑代码的需求。
针对这个思路,我在我们项目中打包设置如下
在Unity项目中脚本剥离功能 可以通过编辑器的 PlayerSetting设置,也可以通过代码设置,下面讲代码设置:
// 支持的方式
public enum StrippingLevel
{
Disabled = 0,
StripAssemblies = 1,
StripByteCode = 2,
UseMicroMSCorlib = 3,
}
// 代码设置
PlayerSettings.strippingLevel = StrippingLevel.StripByteCode;
是的 仅仅一句代码就可以了,我在一键打包脚本中加入了是否添加这句代码的判断。在脚本剥离的时候 遇到几个问题 这里统一给出解决方式:
Q. 我使用了脚本剥离后 有些在UnityEditor.dll的脚本运行的时候找不到了,老提示 Could not produce class with ID XXX 怎么办?
A. 在Assets/Resources 目录下创建一个索引或者 空对象,把相应的脚本挂在上面即可。
举个例子
解决 Could not produce class with ID 91
经过查询Unity官方文档,91对应的脚本是AnimatorController ,所以项目目录下 – 在Resource目录 创建一个 AnimatorController打包进去项目即可解决。
解决 Could not produce class with ID 124
经过查询Unity官方文档,124对应的脚本是 FlareLayer ,所以创建一个空对象 挂一个 FlareLayer 脚本 然后生成一个prefab 丢 Resource目录下即可解决。
Q. 我使用了脚本剥离之后,很多System.dll等的库的脚本都找不到 这是为何啊?
A. 由于脚本剥离 是剥离所有DLL,所以System.dll等脚本也被剥离了,Unity官方推荐的解决方式 是在Assets目录下 加入 link.xml文件。
举个例子
若找不到System.Reflection等类,则在link.xml中加入如下内容:
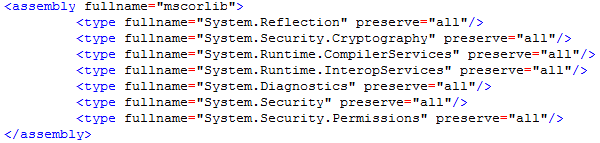
assembly下的 fullname 指的是找不到的类所在的DLL名字
type 下的 fullname 指的是具体的类路径
So。以上即是目前项目中我给出的DLL代码防护方案。欢迎拍砖~
本文完 -EOF-
参考的文章们
- http://www.cnblogs.com/wingkin/p/3454695.html
- http://blog.csdn.net/chiuan/article/details/42456805
- http://docs.unity3d.com/Manual/ClassIDReference.html
- http://www.ceeger.com/Components/class-PlayerSettings.html
- http://www.cnblogs.com/lambdal/p/4524646.html
- http://www.cnblogs.com/fishou/p/4202061.html
- https://shadowkong.com/archives/715
- http://www.cppcourse.com/u3d-encryption.html
- http://blog.csdn.net/ynnmnm/article/details/48784335
- http://blog.csdn.net/forlong401/article/details/8517711
- http://blog.csdn.net/yy405145590/article/details/41205283
- http://www.xuanyusong.com/archives/3571
- http://www.cnblogs.com/24la/p/delete-mono.html
试过几个国外知名 unity 游戏的反编译,感觉他们根本不在意你破不破解。只要氪金没问题,别的地方无所谓。
国内的游戏大厂的防破解就做的很充分,也是恶劣环境造就顶级工程师的经典范例了。
不管如何加密,在运行时都是以解密后的形式存在于内存中,只要把内存全部dump出来,自己写个脚本根据PE文件的特征,就可以剥离出来项目中所有的dll,想问一下作者这个怎么破呢?因为发现TX的目前最火的游戏时dump不出来关键的dll的,但是不知道如何做到的
我认同你说的 , 我们的加密一般只需要防一般的逆向即可 .
我做的方案 (就文中的加密DLL)已经在项目中使用了3年 没出现过什么问题, 哎 大概是没什么人看得上我公司的小软件了…